Visual Methods for Analyzing Probabilistic Classification Data
Journal Article
|
|
| Teaser Image | |
| Author | |
| Abstract |
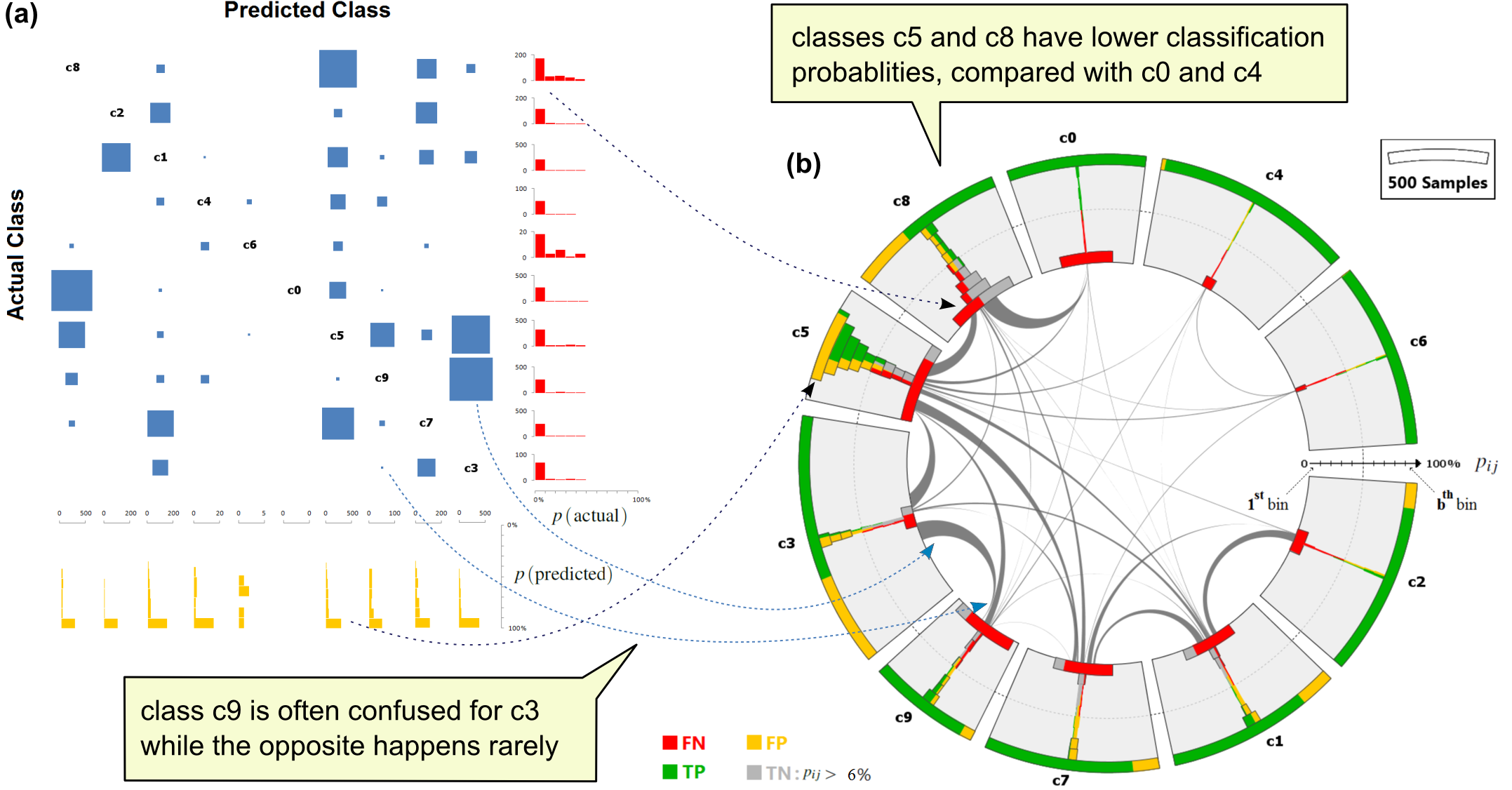
Multi-class classifiers often compute scores for the classification samples describing probabilities to belong to different classes. In order to improve the performance of such classifiers, machine learning experts need to analyze classification results for a large number of labeled samples to find possible reasons for incorrect classification. Confusion matrices are widely used for this purpose. However, they provide no information about classification scores and features computed for the samples. We propose a set of integrated visual methods for analyzing the performance of probabilistic classifiers. Our methods provide insight into different aspects of the classification results for a large number of samples. One visualization emphasizes at which probabilities these samples were classified and how these probabilities correlate with classification error in terms of false positives and false negatives. Another view emphasizes the features of these samples and ranks them by their separation power between selected true and false classifications. We demonstrate the insight gained using our technique in a benchmarking classification dataset, and show how it enables improving classification performance by interactively defining and evaluating post-classification rules.
|
| Keywords | |
| Year of Publication |
2014
|
| Journal |
IEEE Transactions on Visualization and Computer Graphics
|
| Volume |
20
|
| Issue |
12
|
| Number of Pages |
1703--1712
|
| Date Published |
12/2014
|
| DOI | |
| reposiTUm Handle | |
| Internal Projects | |
| Funding projects | |
| Paper | |
| Video Link | |
| Attachments | |
| Supplementary Material | |
| Download citation |

{kind=link}