PDF2Table – Utilizing Table Patterns
If we surf the web we can find PDF files in heaps. Once technical details of an amazing five mega pixel digital camera, once a statistic about the last two years incomes of an enterprise, and once a brilliant crime novel of Sir Arthur Conan Doyle is saved in a PDF file. The widespread use of this file format takes the focus on the question of how to reuse the data in such a file. Many things are already done in this area. For example, there are several tools that convert PDF-files to other formats.
This work focuses on the extraction of table information from PDF-files. Using a tool named pdf2html that extracts basic information from PDF files and returns the data in XML format we developed several heuristics for table detection and table decomposition. Evaluations show that these heuristics work pretty good on lucid tables (without spanning columns and rows) and fairly good on complex tables (with spanning rows or columns).
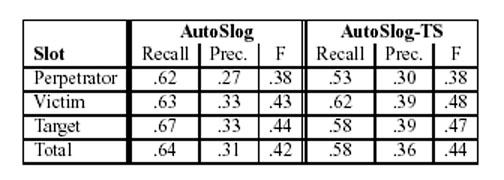
The following table is cutted out of a PDF-file.
pdf2table produces an XML-file with datarow information of the tables in a PDF-file. The extracted information looks, with the corresponding style-sheet, as follows:
| Publications |
Burcu Yildiz. Information Extraction - Utilizing Table Patterns, Masters thesis, Vienna University of Technology, 2004. Burcu Yildiz, Katharina Kaiser, Silvia Miksch. pdf2table: A Method to Extract Table Information from PDF Files , In: Proceedings of the 2nd Indian International Conference on Artificial Intelligence (IICAI05), Pune, India, 2005. |
|---|---|
| Related Work |
|